1. 引言
1.1 研究背景
- 技术和产品迭代升级较快导致目前市场大多数分析无时效性,且往往缺少对产品的实际测试以及对相同提示词的比较分析,而AI视频生成正成为当前 AI产业发展的关键节点。视频杂糅了文本、语音、图像等多维度内容,其训练的难点也往往在于视频数据对数量和质量的不足、算法架构需要优化、物理规律性较差等等,但随着AI+视频的技术和产品升级迭代,众多行业有望受益,诸如电影、广告、视频剪辑、视频流媒体平台、UGC创作平台、短视频综合平台等,而目前正处在AI+视频发展的关键性时刻。
- 市场主流AI视频生成技术迭代路径经历了早期GAN+VAE、Transformer、Diffusion Model以及Sora采用的DiT架构,技术迭代升级带来视频处理质量上的飞跃性提升。VAE引入了隐变量推断,GAN生成的图像真实清晰,VAE+GAN的串联融合可以实现数据的自动生成+高质量图像生成;Transformer在并处处理、长时间序列数据处理、多注意力处理上有着强大的优势,通过预训练和微调可提高模型性能;扩散模型可解释性强,可生成高质量图像和视频;李飞飞联合谷歌研发的WALT视频大模型将图像和视频编码到共享潜在空间中。Sora采用的DiT架构有效进行结合,利用 Transformer处理潜在空间中的图像数据块,模拟数据的扩散过程以生成时长更长、质量更高的图像和视频。
1.2 核心观点
- 国内AI+视频产品单条价格低于海外产品,其中 Runway Gen-3 Alpha和快手可灵为目前AI视频生成的全球第一梯队,在视频分辨率、生成速度、物体符合物理规律、提示词理解、视频时长等诸多维度上表现均较为优秀。核心梳理国内和海外市场AI视频生成的核心参与者,如海外Luma AI(Dream Machine)、Runway(Gen 1-2 & Gen-3 Alpha)、Pika、Sora,国内快手可灵、美图、PixVerse、剪映即梦、清华 Vidu、七火山 Etna 等,集中梳理了众多产品的融资历程、产品迭代、核心功能、实测效果比较等多方面。经过百森测算,目前AI+视频主流产品的单条视频生成价格分别为:Luma AI 0.16美元(1.17rmb)、Pika0.05美元(0.364rmb)、Runway 0.48 美元(3.49rmb)、快手可灵0.5rmb、字节剪映即梦0.04rmb、爱诗科技Pixverse V2为0.02美元(0.174rmb)、美图WHEE为0.32rmb,国内AI+视频产品单条价格较低,质量不差。
- 不止于视频生成,从AI生成到AI工作流,一站式AI视频生成+剪辑+故事创作有望成为产业核心发展方向。目前,AI+视频大多数用于创意内容生成,直接用于ToB商业化较少。追溯原因,首先生成视频的人物一致性、所需时长、画面质量尚且不满足立即商业化水准。其次,百森发现目前主流AI视频工具还处在视频生成竞争的阶段,且大多数为单一功能产品。在视频生成之后,诸如准确的提示词生成、修改视频片段、添加字幕、脚本生成、转场衔接、背景音乐添加等众多细节功能暂未集成,因此现今阶段还需要多种不同的视频创作工具串联使用才能达到直接输出可商业化视频的效果,环节繁琐、多工具之间的格式也可能存在不兼容的可能性,给用户带来使用上的不便。因此百森认为,后续需要持续关注能够一站式提供视频生成+编辑等功能的企业,了解用户痛点,打磨产品细节,才能真正将技术用于生产工作、娱乐等众多环节,带来商业化变现的潜在空间。一站式AI视频生成&剪辑&UGC创作有望解决市场一直在质疑的“AI+视频没有实质作用问题”。
2. 行业发展
2.1 关键节点
- 在历经文生文、文生图的升级迭代后,我们目前正处在AI+生产力办公&设计、AI+视频和AI+3D渗透的历史节点上。在底层大模型技术迭代逐渐加速的今天,AI文本对话、AI文生图、AI陪伴等方向已经逐渐成为竞争激烈的主要方向,展望未来我们需要对更多AI+做深入的研究,而视频方向一直是业内关注的重点方向之一。视频杂糅了文本、语音、图像等多维度内容,其训练的难点也往往在于视频数据对数量和质量的不足、算法架构需要优化、物理规律性较差等等,但我们相信,随着AI+视频的技术和产品升级迭代,众多行业有望受益,诸如电影、广告、视频剪辑、视频流媒体平台、UGC创作平台、短视频综合平台等,而目前正处 AI+视频发展的关键性时刻,正从AI+视频创意生成逐渐过渡到一站式视频生成+剪辑+UGC的后续阶段。

2.2 发展趋势
- 生成式人工智能从技术趋势演变为实际应用和价值,以及生成式人工智能应用日益呈现多模态的特性。可以看到,AI视频生成及编辑的版图占比较多,重要性和产品推进速度目前较快。
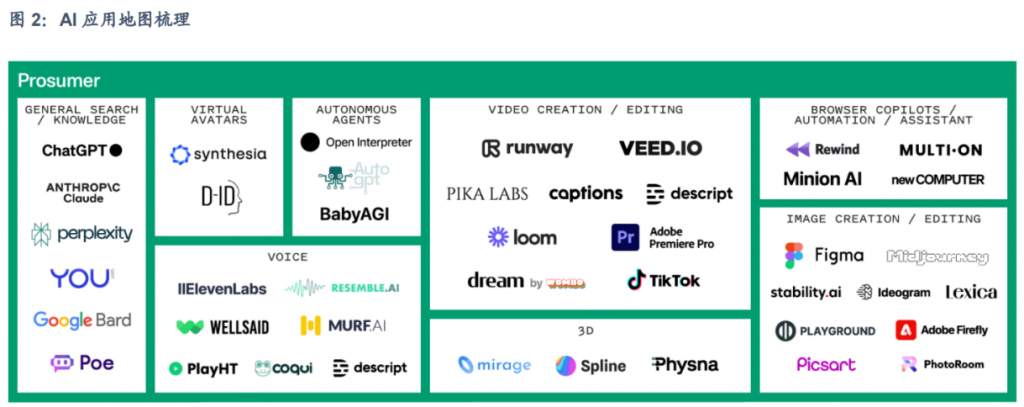
2.3 面临挑战
- 计算成本:确保帧间空间和时间一致性会产生长期依赖性,从而带来高计算成本。
- 缺乏高质量的数据集:用于文生视频的多模态数据集很少,而且通常数据集的标注很少,这使得学习复杂的运动语义很困难。文生视频模型需要依赖于大量数据来掌握如何将文本描述转化为具有写实感的连续帧,并捕捉时间上的动态变化。
- 视频生成质量:时空一致性难以保持,在不同镜头、场景或时间段内较难确保角色、物体和背景的一致性。可控性和确定性还未充分实现,确保所描述的运动、表现和场景元素能够精确控制和编辑。视频时长的限制,长视频制作仍面临时间一致性和完整性的挑战,这直接影响到实际应用的可行性。
- 语义对齐:由于自然语言具有复杂性和多义性,文本语义理解、文本与视频元素的映射关系仍是挑战。
- 产品易用性:对于文生视频,产品的易用性和体验仍需改进。个人用户希望制作流程易上手、符合习惯,并支持快速素材搜索、多样模板、多端同步和一键分享;小B端用户关注成本可控下的快速营销视频制作和品牌传播效果;行业用户则需要内容与交互性的融合,包括商用素材适配性、快速审核和批量制作分发能力。
- 合规应用:文生视频的应用面临素材版权、隐私安全和伦理道德等风险。
3. 技术概述
3.1 技术迭代路径
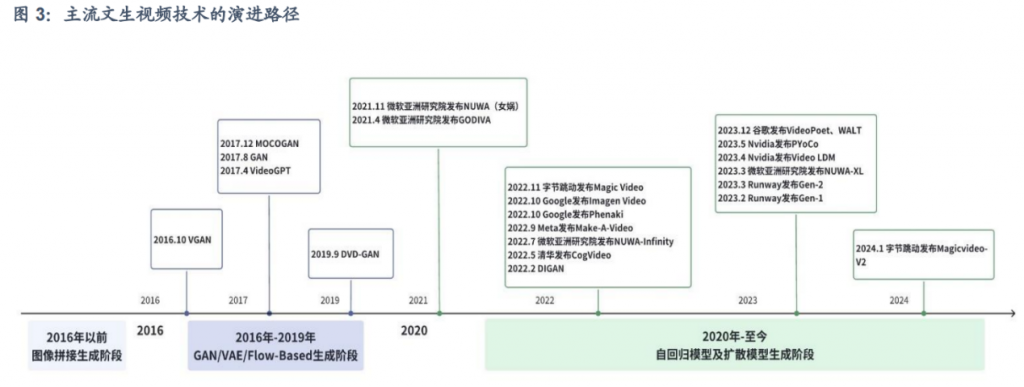
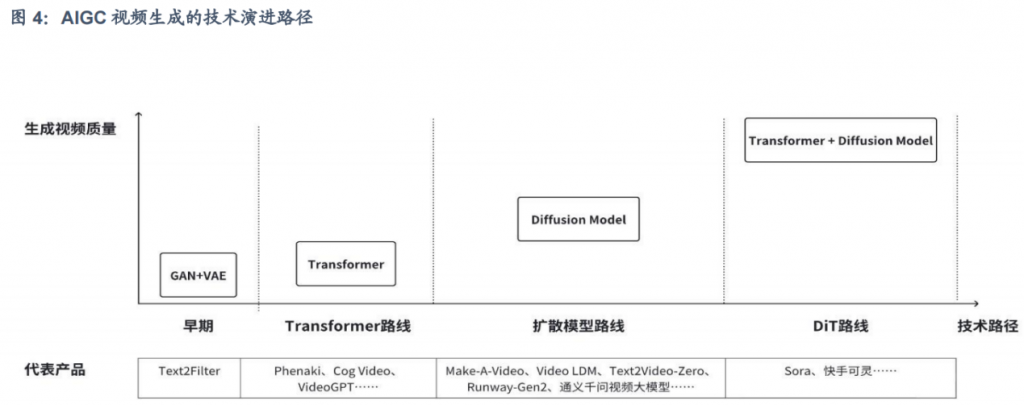
3.2 核心技术概述
(1)GAN+VAE
- 生成对抗网络(Generative Adversarial Networks)核心思想是训练两个网络,生成器(G)和判别器(D)。生成器通过获取输入数据样本并尽可能对其进行修改来生成新数据,试图生成逼真的视频;而判别器尝试预测生成的数据输出是否属于原始数据集,尝试区分真实视频和生成的视频。两个网络通过对抗训练,生成器试图最大化欺骗判别器,而判别器则试图最大化识别生成视频的错误,直到预测网络不再能够区分假数据值和原始数据值。
- GAN用于视频生成在2016年至2021年较为火热,代表模型如Temporal Generative Adversarial Nets (TGAN)和MoCoGAN,它们通过不同的网络架构和训练方法来改进GAN在视频生成上的性能。此外,Dual Video Discriminator GAN (DVD-GAN) 通过使用空间和时间判别器的分解来提高视频生成的复杂性和保真度。
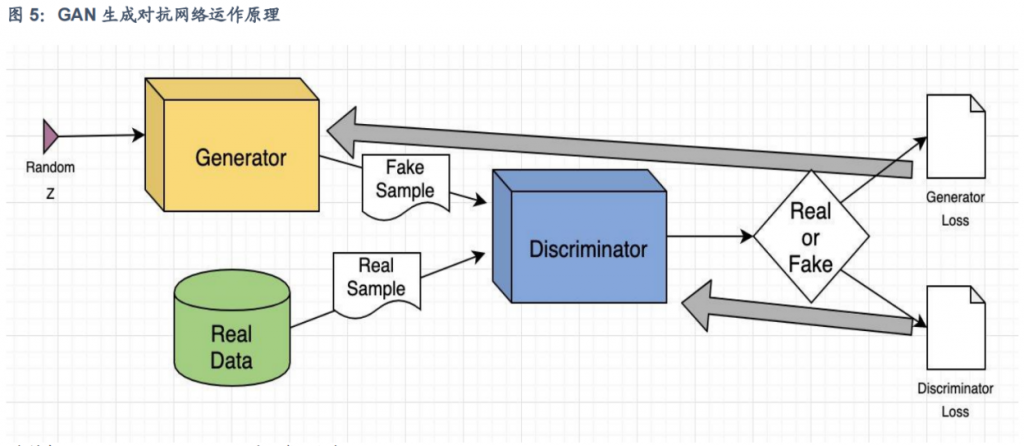
- GAN 技术特点如下:1)无需标注数据,可以从未标注的图像中学习生成新的图像或视频;2)多领域应用,可以应用于图像生成、风格迁移、数据增强、超分辨率等多种任务;3)模型灵活,通过改变网络结构,可以适应不同的数据分布和生成任务;4)模型参数小,较为轻便,擅长对单个或多个对象类进行建模。GAN 作为早期文生视频模型,存在如下缺点:1)训练过程不稳定,容易出现模式崩溃(mode collapse),即生成器开始生成非常相似或重复的样本;2)计算资源:训练GAN通常需要大量的计算资源和时间;3)对超参数选择敏感,不同的设置可能导致训练结果差异很大。
- VAE(Variational Autoencoder变分自编码器):对于传统的基本自编码器来说,只能够对原始数据进行压缩,不具备生成能力,基本自编码器给定一张图片生成原始图片,从输入到输出都是确定的,没有任何随机的成分。 生成器的初衷实际上是为了生成更多“全新”的数据,而不是为了生成与输入数据“更像”的数据。而变分自用编码器的 Encoder与Decoder在数据流上并不是相连的,不会直接将Encoder编码后的结果传递给Decoder,而是要使得隐式表示满足既定分布。因此,VAE引入了隐变量推断,训练过程稳定,但是其生成的图片缺少细节,轮廓模糊;GAN生成的图像真实清晰,但是训练过程易出现模式崩溃问题。因此,VAE+GAN的串联融合可以实现数据的自动生成+高质量图像生成的结果。
(2)Transformer 模型
- Transformer是一种先进的神经网络算法,它完全基于注意力机制,不依赖于传统的循环神经网络(RNN)或卷积神经网络(CNN)。Transformer保留了编码器-解码器的基本结构。编码器将输入序列映射到连续的表示空间,而解码器则基于这些表示生成输出序列。Transformer模型的自注意力机制,允许序列中的每个元素都与序列中的其他元素进行交互,从而捕捉全局依赖关系;模型还采用多头注意力并行处理,可获取不同空间的信息。
- Transformer 模型技术特点如下:1)并行处理序列中的所有元素,这与传统循环神经网络(RNN)相比,大大提高了计算效率;2)可扩展性,能够通过堆叠多个注意力层来增加模型的复杂度和容量;3)泛化能力,除了语言任务,还可以泛化到其他类型的序列建模任务,如图像处理、视频分析等;4)预训练和微调,Transformer模型通常先在大量数据上进行预训练,再针对特定任务进行微调,使得模型能够快速适应新任务;5)适应长序列数据,在处理诸如语音信号、长时间序列数据等任务具有优势,避免传统模型存在的梯度消失或梯度爆炸问题。
- Transformer 存在如下缺点:1)参数效率相对较低,参数数量随输入序列长度的增加而增加,增加了训练时间和成本;2)对输入数据的敏感性较高,模型依赖于输入数据的全局信息进行建模,在处理复杂任务时(如机器翻译、语音识别等),对输入数据的细微变化可能会对模型的输出结果产生较大影响;3)难以处理时空动态变化,模型时基于自注意力机制的静态模型,无法捕捉到时空动态变化的信息,因此在处理视频、时空数据等具有动态变化特性的任务时,需要结合其他技术来提高模型的性能。Transformer模型在视频生成领域的应用的产品包括VideoGPT、NUWA、CogVideo、Phenaki 等。这些模型通过结合视觉和语言信息,生成新的视频内容或对现有视频进行操作。它们利用了Transformer 模型的自注意力机制来处理高维数据,并通过预训练和微调策略来提高性能。此外,这些模型还探索了如何通过多模态学习来提高视频生成的质量和多样性。
(3)扩散模型
- 扩散模型是一种生成模型,通过逐步添加噪声来破坏训练数据,然后通过逆向过程去噪来生成与训练数据相似的新数据。扩散模型分为三大类型:去噪扩散概率模型(DDPM)、基于噪声条件评分的生成模型(SGM)、随机微分方程(SDE),但三种数学框架背后逻辑统一,均为添加噪声后将其去除以生成新样本。
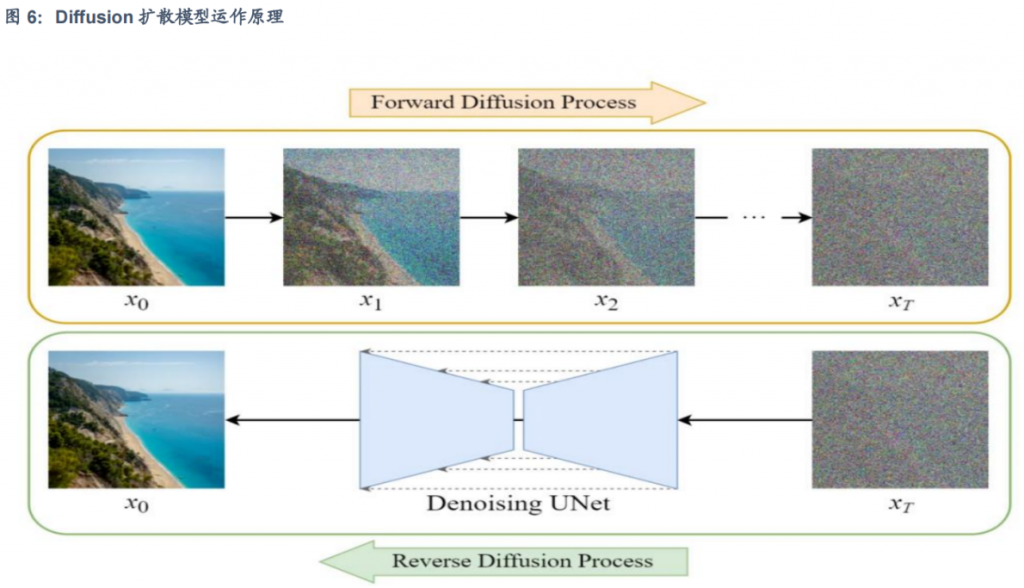
- 尽管Transformer在Autoregressive Model中得到广泛应用,但是这种架构在生成式模型中较少采用。比如,作为图像领域生成模型的经典方法,Diffusion Models却一直使用基于卷积的U-Net架构作为骨干网络。随着 Sora、WALT等基于(Diffusion+Transformer)的探索,国内创业公司如智向未来也在尝试延续这个最新的技术路线,用Transformer架构替换掉原来的卷积U-Net架构后,生成视频的时长可变、尺寸可变,可以在不同的空间进行建模,同时也可以让视频和图片配对来实现多模态对齐与编码。
(4)Dit模型
- Diffusion Transformer(DiT)模型是从(Scalable Diffusion Models with Transformers, ICCV 2023)中引入。基本上,Diffusion Transformer(DiT)是一个带有变换器(而非U-Net)的扩散模型,核心思想是利用 Transformer处理潜在空间中的图像数据块,模拟数据的扩散过程以生成高质量的图像。
- DiT模型技术特点如下:1)运用潜在扩散模型,在潜在空间而非像素空间中训练扩散模型,提高了计算效率;2)Patchify 操作,将空间输入转换为一系列 token,每个 token 代表图像中的一个小块;3)条件输入处理,DiT设计了不同的 Transformer 块变体来处理条件输入(如噪声时间步长、类别标签等);4)自适应层归一化(adaLN),使用adaLN来改善模型性能和计算效率;5)可扩展性:DiT展示了随着模型大小和输入token数量的增加,模型性能得到提升;6)简化的架构选择,DiT证明了在扩散模型中,传统的U-Net架构并不是必需的,可以被Transformer替代。
- DiT模型仍存在以下缺点:1)实现复杂性,虽然DiT在理论上简化了架构选择,但Transformer的实现可能比U-Net更复杂;2)训练稳定性:尽管 DiT 训练稳定,但Transformer架构可能需要特定的训练技巧来保持稳定;3)对硬件要求高,虽然DiT在计算上更有效率,但Transformer模型通常需要大量的内存和计算资源,这可能限制了它们在资源受限的环境中的应用;4)模型泛化能力,DiT主要在ImageNet数据集上进行了评估,其在其他类型的数据和任务上的泛化能力尚未得到验证。
- DiT作为一种新型的扩散模型,通过在潜在空间中使用Transformer架构,实现了对图像生成任务的高效和高性能处理。DiT在Sora上表现优秀,Sora 是OpenAI发布的爆款视频生成模型,它融合了扩散模型的生成能力和Transformer架构的处理能力。受到大规模训练的大型语言模型的启发,Sora通过在互联网规模的数据上训练,获得了通用化的能力。它采用基于扩散模型的生成框架,逐步改进噪声样本以产生高保真度的视频输出,并应用Transformer架构来处理视频和图像的时空信息,保持物体在三维空间中的连贯性。这种结合生成和变换器优势的方法,使得Sora在视频生成和编辑任务中表现出色,能够创造出多样化、高质量的视觉内容。
4. 海外市场参与主体
4.1 AI+视频背景
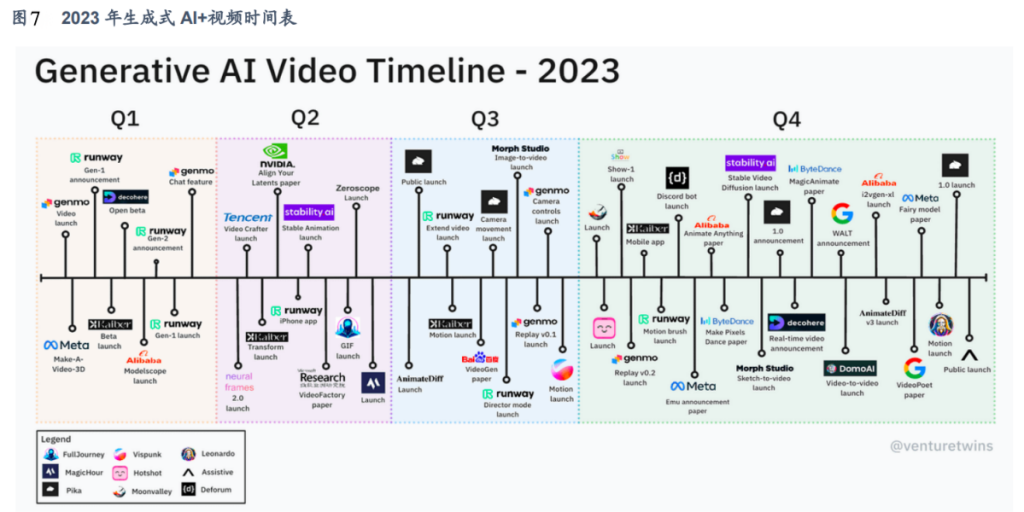
- AI+视频发展以来,技术路径和迭代产品冗杂繁多、功能不一、效果差异,我们选取目前海内外市场主要的生成式视频的参与者:Luma AI(Dream Machine)、Runway(Gen 1-2 & Gen-3 Alpha)、Pika、Sora,集中梳理了其融资历程、产品迭代、核心功能、实测效果比较等多方面,经个别提示词生成视频效果测试,在Sora未公开实测情况下,我们认为 Runway Gen-3 Alpha 的视频生成效果,如质量分辨率、生成速度、物体符合物理规律、提示词理解、视频时长等诸多维度上表现均较为优秀。
4.2 参与主体
(1)Luma AI—Dream Machine
- Luma AI成立于2021年,2024 年以其推出的文生视频模型Dream Machine而得到全球投资视野的关注,但早期公司仅聚焦在3D内容生成,23年11月,Luma AI在Discord 服务器上推出了文生3D模型 Genie,降低了开发人员的3D建模和重建功能的成本,每个场景或者物体的生成只需一美元,创建时间也大幅缩短。公司推出的应用程序Flythroughs可以使用户仅使用AI和iPhone就可创建专业的飞行场景视频,可用于房产中介应用的3D环境视频的录制等。融资历程:公司 A 轮融资由 Amplify Partners、Nventures(Nvidia 投资部门)和 General Catalyst 领投,共筹集 2000 万美元;B 轮融资则由硅谷顶级风投公司 Andreessen Horowitz、英伟达领投,筹集4300万美元,B轮估值在2亿到3亿美元之间。官网显示目前核心团队共34人,其中华人5位。
- Luma AI Dream Machine 是一款由 Luma AI开发的AI视频生成模型,它能够将文本和图像快速转换为高质量、逼真的视频,且具备前后帧输入图片生成连贯视频的功能。在官网的介绍中,该模型具备快速视频生成能力,能够在120秒内生成120帧视频,可生成具有逼真流畅动作、电影摄影和戏剧效果5s镜头,确保视频角色的一致性和物理准确性,适用于创意视频制作、故事讲述、市场营销及教育培训等多种场景。Dream Machine可以快速将文本和图像制作成高质量视频、是一种高度可扩展且高效的转换器模型,能够生成物理上准确、一致且多变的镜头。
(2)Runway Gen 1-2 & Gen-3 Alpha
- Runway成立2018年,总部位于纽约,由Cristóbal Valenzuela、Alejandro Matamala和Anastasis Germanidis共同创立。公司专注于将艺术与人工智能融合,提供图像和视频编辑工具。自成立以来,Runway经历了多轮融资,估值迅速增长。其产品包括多种AI驱动的创作工具,如2023年推出的Gen-1和Gen-2,Runway仍在不断创新,2024年推出新一代视频生成模型Gen-3 Alpha。据外媒TechCrunch报道,近期公司正筹划新一轮融资4.5亿美元,估值有望达到40亿美元。
- Runway 不同的定价模式:主要分为永久免费基础版、标准版、高级版、无限制版本和企业级版本服务。永久免费版:用户拥有一次性125个credits 积分,gen-1(视频到视频)上传最长为4s,gen-2(文生视频和图生视频)通过延长视频功能最长至16s等;标准版、高级版和无限制版本的差别在于每月积分的数额、gen-3的使用、水印的消除、资产库数量、视频质量等方面。
5. 国内市场参与主体
5.1 快手—可灵AI
- 快手的大模型能力涵盖了包括大语言模型、文生图大模型、视频生成大模型、音频大模型、多模态大模型等核心技术方向,并基于快手丰富的业务场景,将生成式 AI 与多模态内容理解、短视频 /直播创作、社交互动、商业化 AIGC、创新应用等业务形态深度结合。可灵大模型的更新迭代速度较快,当视频生成效果接近图形渲染和视频拍摄时,有望对游戏、动画、泛视频行业带来新的机遇,有望促进视频平台生态繁荣。
- 自研“快意大模型”(KuaiYii):13B、66B、175B 三种参数规模,将大模型应用于短视频场景下。
- 可图大模型(KOLORS):由快手大模型团队自研打造的文生图大模型,具备强大的图像生成能力,能够基于开放式文本生成风格多样、画质精美、创意十足的绘画作品。“可图”主打三大核心特性:深入的中文特色理解、长文本复杂语义理解及对齐人类审美的精美画质,让用户低门槛创造高质量图像。
- 可灵视频生成大模型:2024年6月6日,快手大模型团队自研打造了视频生成大模型—可灵,具备强大的视频生成能力,让用户可以轻松高效地完成艺术视频创作,包含文生视频能力、图生视频能力及视频续写能力,后续有望上线视频编辑功能。可灵视频模型的重点方向在于:大幅度的合理运动符合物理规律、长达2分钟的视频生成能力帧率且达到30fps、模拟物理世界特性、强大的概念组合能力、电影级别的画面、支持自由的输出视频高宽比。在2024年世界人工智能大会上,快手可灵AI产品宣布全新升级:高清画质、首尾帧控制、单次生成10s、Web端上线、镜头控制。
5.2 美图MiracleVision4.0 AI视频
- 2023年12月,美图公司发布自研AI视觉大模型MiracleVision 4.0版本,主打AI设计与AI视频。新增了文生。视频、图生视频、视频运镜、视频生视频四大能力。目前,MiracleVision的AI视频能力已能融入行业工作流,尤其是电商和广告行业。MiracleVision4.0于2024年1月陆续上线至美图旗下产品。目前生成一次视频需要消耗10美豆,实际测验下来看,其对提示词的理解、物体的像素质量、物理规律、动作的自然效果,尤其是对人物和物体的细节处理上较为优秀,例如动物的毛发帧数。图生视频功能:让图片也动起来。从景深变化到细节动作捕捉,MiracleVision可以轻松生成。非常的自然流畅。图生视频的基础上,MiracleVision 支持视频运镜。提供了推、拉、摇、移等八种电影级运镜模式,让用户能够轻松模拟专业的镜头运动。后续有望更新视频生视频功能,导入一段视频,再加上不同的提示词,就能获得卡通、科幻、像素风,羊毛毡等不同的艺术风格。
5.3 PixVerse 爱诗科技
- 爱诗科技Alsphere成立于2023年4月,海外版产品PixVerse于2024年1月正式上线,目前已是全球用户量较大的国产AI视频生成产品,上线88天,PixVerse视频生成量已达一千万次。公司早期完成数千万人民币天使轮融资,2024年3月公司完成亿级人民币A1轮融资,国内一线投资机构达晨财智领投。创始人王长虎博士深耕计算机视觉与人工智能领域 20 年,带领字节跳动视觉技术团队在巨量规模的用户数据下,解决了多个视觉领域的世界级难题,并从0到1参与抖音与Tik Tok等国民级视觉产品的建设和发展,公司团队成员来自清华、北大、中科院等顶级学府,曾任职于字节、微软亚洲研究院、快手、腾讯的核心技术团队。基于“数据、算法和工程” 三大要素,解决“准确性”和“一致性”,用更少资源取得更优效果。公司致力于通过——“融合内容理解与生成;融合文字、图片、视频等多模态”的双融合技术路径,搭建世界一流的AIGC视觉多模态大模型。
5.4 即梦 Dreamina
2024年5月,字节剪映旗下针对AI创作产品Dreamina正式更名为中文“即梦”,AI 作图和AI视频生成功能已经上线,用户可输入文案或者图片,即可得到视频动态效果连贯性强、流畅自然的视频片段。创新打造首帧照片和尾帧照片输入方式,增强视频生成的可控性,支持中文提示词创作,把握语义。2024年6月17日,上海国际电影节期间,由抖音、博纳影业 AIGMS 制作中心联合出品的AIGC科幻短剧集《三星堆:未来启示录》亮相“博纳 25 周年’向新而生’发布会”。即梦AI作为《三星堆:未来启示录》首席 AI 技术支持方,借助包括AIGC剧本创作、概念及分镜设计、图像到视频转换、视频编辑和媒体内容增强等十种AIGC技术,重新为古老IP注入新故事、开发新内容。在产品使用界面,即梦添加了更多用户可控的细节功能,例如运镜控制的种类中,可自行选择移动方向、摇镜方向、旋转角度、变焦程度、幅度大小等,省去用户提示词中复杂的表述;用户还可自行选择运动速度、标准/流畅模式、生成时长和视频比例等,UI界面更容易被用户接受,简单易行。